We are proud to announce that we will be at the computer graphics conference SIGGRAPH Asia 2018 this December, where we will present the techniques used to create our 64K intro, H – Immersion.
At the conference, the “Computer Animation Festival” celebrates storytelling and animation in general, and showcases some of the best works of the year. We are honoured to have been selected among the talks there, and still in disbelief to be sitting next to talks about Pixar’s Incredibles 2 or Solo: A Star Wars Story.
If you are attending SIGGRAPH Asia this December in Tokyo, come to our session on Thursday 6th of December, from 16:15 to 18:00, in room G502 (glass building, fifth floor). All the details are available on the SIGGRAPH Asia 2018 session description. There is an iCalendar file as well.
Tomasz Bednarsz has been trying to increase the presence of demoscene at the major graphics community conference, SIGGRAPH, for a few years now, through so called “Birds of a Feather” sessions. This year I had the unexpected opportunity to attend SIGGRAPH in Vancouver, and I was invited to participate to the session along with a few other sceners. The details are available on the description that Tomasz posted.
There, I presented some aspects of 64k creation, that Laurent and I have been discussing here in the recent articles. The slides are available here:
A recording of the entire session is available. It includes the introduction by Tomasz, a presentation of a technique to render clouds in real time by Matt Swoboda (Smash, of Fairlight), our part, another take on 64k creation by Yohann Korndörfer (cupe of Mercury), and a presentation of Tokyo Demo Fest by Kentaro Oku (Kioku, of SystemK).
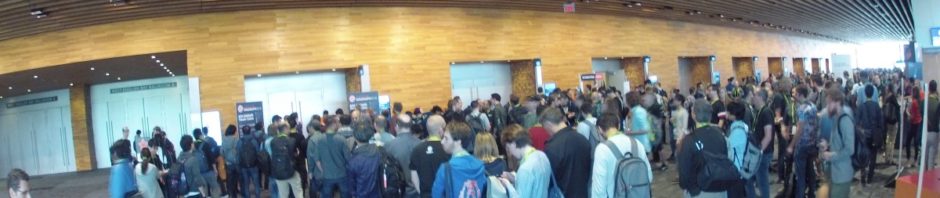
The event was way more successful than any of us expected, and we were all gladly surprised to see so much interest from the graphics community. A lot more people showed up than the room could accommodate, meaning that unfortunately most of them had to walk away.
The waiting line for the Birds of a Feather session on demoscene, at SIGGRAPH 2018.
Hopefully this increased interest means we can expect more events like this to happen at SIGGRAPH in the future years. We are already planning to do another demoscene session at SIGGRAPH Asia 2018, which will take place in Tokyo on December 4th to 7th.
When making an animation within only 64kB, using images is tricky. We can’t store them in a traditional way, because it is not efficient enough, even with a compression like JPEG. An alternative solution is procedural generation. It consists in using code to describe how to create the images at runtime. Our implementation of such a solution is the texture generator, a core part of our toolchain. In this post we will present how we designed it and how we used it in H – Immersion.
The spotlights of a submersible reveal details of the seafloor.
Early version
Texture generation has been one of the earliest elements of our code base: our first intro, B – Incubation, already had procedural textures. The code consisted in a set of functions to fill, filter, transform and combine textures, and one big loop to go over all the textures. Those functions were written in plain C++, but were later exposed with a C API so they could be evaluated by a C interpreter, PicoC. At the time, we were using PicoC in an effort to reduce iteration time: in this case it allowed to modify and reload the textures at runtime. Limiting ourselves to the C subset was a small price to pay for the ability to change code and see the result without having to quit, compile and reload the entire demo again.
With a simple pattern, some noise and some deformation, we can obtain a stylized wood texture.
Various wood textures are used in this scene from F – Felix’s workshop.
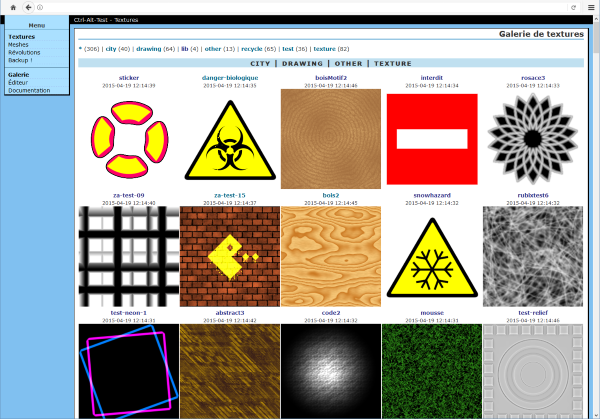
We explored for a while what we could do with that generator, and ended up putting it on a web server with a small PHP script behind a simple web interface. We would write texture code in a text field, the script would feed it to the generator, which would then dump the result as a PNG file for the page to display. Soon enough, we found ourselves doodling from the office during lunch breaks and sharing our little creations among group members. This interaction was very motivating for creativity.
Our old texture generator web gallery. All the textures were editable in the browser.
A complete redesign
For a long time the texture generator almost didn’t change; we thought it was fine and our efficiency plateaued. Then we woke up one day, and discovered that Internet forums were suddenly full of artists showing off their 100% procedurally generated textures and challenging each other with themes. Procedural content used to be a demoscene thing, but Allegorithmic, ShaderToy and the likes had now made it accessible to the crowd while we had not been paying attention, and they were beating us hard. Unacceptable!
Fabric Couch
Forest Floor
It was long due time to reevaluate our tools. Fortunately working with the same texture generator for several years had given us time to understand its flaws. Our nascent mesh generator was also giving us some additional perspective on what we wanted a procedural content pipeline to look like.
The most important architecture mistake was the implementation of generation as a set of operations on textures objects. From a high level perspective, it may be a correct way of viewing it, but at the implementation level, having functions like texture.DoSomething() or Combine(textureA, textureB) has severe drawbacks.
First, the OOP style requires to declare those functions as part of the API, no matter how simple they are. This is a major problem because it doesn’t scale well and more importantly, it creates friction in the creation process. We don’t want to change the API every time we try something new. It makes experimentation more difficult, and ultimately limits artistic creativity.
Second, in terms of performance, it forces to loop over texture data as many times as there are operations. It wouldn’t matter too much if those operations were expensive relative to the cost of accessing large chunks of memory, however that’s usually not the case. Except for a few operations like generating a Perlin noise or doing a flood fill, most are in fact very simple and require few instructions per texture point. This means we keep traversing texture data to do trivial operations, which is ridiculously cache inefficient.
The new design addresses those issues with a simple reorganization of the logic. In practice, the majority of the functions just do the same operation for each element of the texture, independently. So instead of writing a function texture.DoSomething() which goes through all the elements, we can write texture.ApplyFunction(f) where f(element) only works on a single texture element. f(element) can then be written ad hoc for a specific texture.
This seems to be a minor modification. Yet doing so simplifies the API, makes the generation code more flexible and more expressive, is more cache friendly and trivially parallelizable. Many of you readers will probably recognize this as being essentially… a shader. Although the implementation is still, in fact, C++ code running on the CPU. We also keep the ability to do operations outside of the loop like before, but we only use that option when it is relevant, for example when doing a convolution.
Before:
// Logic is at the texture level.
// The API is bloated.
// The API is all there is.
// Generation of a texture has many passes.
class ProceduralTexture {
void DoSomething(parameters) {
for (int i = 0; i < size; ++i) {
// Implementation details here.
(*this)[i] = …
}
}
void PerlinNoise(parameters) { … }
void Voronoi(parameters) { … }
void Filter(parameters) { … }
void GenerateNormalMap() { … }
};
void GenerateSomeTexture(texture t) {
t.PerlinNoise(someParameter);
t.Filter(someOtherParameter);
… // etc.
t.GenerateNormalMap();
}
After:
// Logic is usually at the texture element level.
// The API is minimal.
// Operations are written as needed.
// Generation of a texture has a reduced number of passes.
class ProceduralTexture {
void ApplyFunction(functionPointer f) {
for (int i = 0; i < size; ++i) {
// Implementation passed as a parameter.
(*this)[i] = f((*this)[i]);
}
}
};
void GenerateNormalMap(ProceduralTexture t) { … }
void SomeTextureGenerationPass(void* out, PixelInfo in) {
result = PerlinNoise(in);
result = Filter(result);
… // etc.
*out = result;
}
void GenerateSomeTexture(texture t) {
t.ApplyFunction(SomeTextureGenerationPass);
GenerateNormalMap(t);
}
Parallelization
Generating textures takes time, and an obvious candidate for reducing that time is to have parallel code execution. At the very least, it is possible to generate several textures concurrently. This is what we did up to F – Felix’s workshop and it greatly reduced loading time.
However, doing so doesn’t shorten generation time where we most want it. Generating a single texture still takes as much time. That affects editing, when we keep reloading the same texture again and again between each modification. It is preferable to parallelize the inner texture generation code instead. Since the code now essentially consists in just one big function applied in a loop to each texel, parallelization becomes very simple and efficient. The cost of experimenting, tweaking and doodling is reduced, and that directly impacts creativity.
A damaged mosaic texture for H – Immersion
A mosaic texture for H – Immersion
This illustration is an idea that we explored and abandoned for H – Immersion: a mosaic decoration with orichalcum lining. It is shown here in our live editing tool.
GPU side generation
In case it isn’t completely clear in the paragraphs above, texture generation is done entirely on the CPU. At this point some of you might be staring at these lines with incredulity and thinking: “But, why?!”. Generating textures on the GPU would seem like the obvious thing to do. For starters it would likely speed up generation by an order of magnitude. So, why?
The main reason is that it was a smaller step of redesign to stay on CPU. Moving to GPU would have been more work. It would have required to solve additional problems, new problems we don’t have enough experience with yet. On CPU we had a good understanding of what we wanted and how to fix some of the earlier mistakes.
The good news however, is that with the new design it now seems fairly trivial to experiment with GPU side generation as well. In the future, testing combinations of both could be an interesting path to explore.
Texture generation and physically based shading
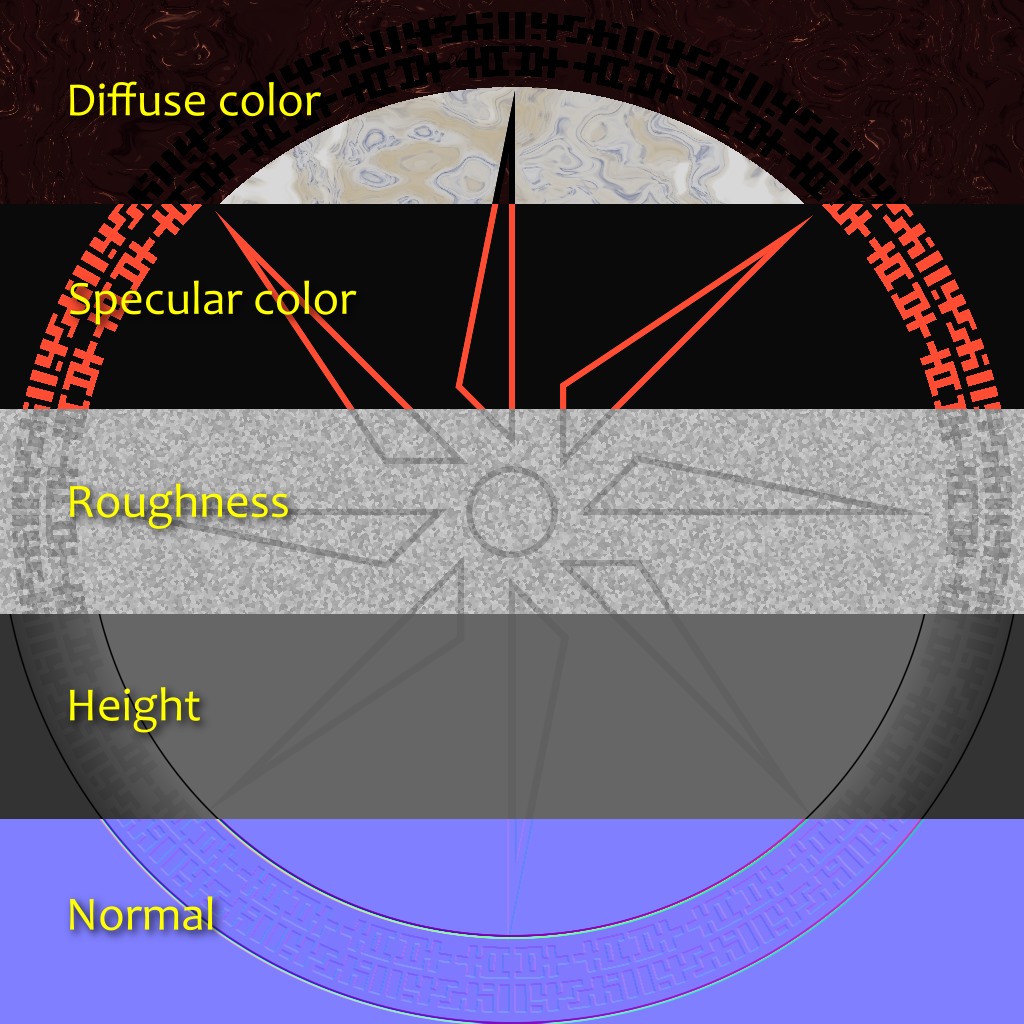
Another limitation of the old design was that a texture was considered to be just an RGB image. If we wanted to generate more information, say, a diffuse texture and a normal texture for a same surface, nothing was preventing us from doing that, but the API wasn’t actively helping either. This takes special importance in the context of Physically Based Shading (PBR).
In a traditional non-PBR pipeline, surfaces typically use color textures in which a lot of information is baked. Those textures often represent the final appearance of the surface: they already have some volume, the crevices are darkened, and they may even have some reflection highlights. If more than one texture is used at a time, it’s usually to combine details of large and small scale, to add normal mapping, or to represent how reflective the surface is.
In a PBR pipeline on the contrary, surfaces tend to use sets of different textures that represent physical values rather than a desired artistic result. The diffuse color texture, which is the closest to what we commonly describe as “the color” of a surface, typically looks flat and uninteresting. The specular color is dictated by the surface index of refraction. Most of the detail and variety come from the normal and the roughness textures (which you could argue represent the same thing, but at two different scales). How reflective the surface feels just becomes a consequence of the roughness. At this point, it makes sense not to think in terms of textures anymore, but in terms of materials.
Greetings marble floor texture breakoff
Cobbles textures breakoff
Fountain scene in H – Immersion
Seafloor textures breakoff
Seafloor scene in H – Immersion
Old stone textures breakoff
Arch scene in H – Immersion
Submersible body texture breakoff
Launch scene in H – Immersion
The current design allows to declare arbitrary pixel formats for textures. By making it part of the API, we can have all the boilerplate taken care of. Once the pixel format is declared, we can focus on writing the creative code, without spending additional effort on processing that data. Upon execution, it will generate several textures and upload them to the GPU, transparently.
Some PBR workflows don’t directly expose diffuse and specular colors, but instead a “base color” and a “metalness” parameter, which have some advantages and some disadvantages. In H – Immersion we use a diffuse+specular model, and a material usually consists of 5 layers:
Relief elevation (A; used for parallax occlusion mapping).
When it was used, emissive detail was added directly in the shader. It didn’t seem necessary to have ambient occlusion either since most scenes didn’t have ambient light at all. It wouldn’t be surprising to have such additional layers though, or other kind of information like anisotropy or opacity for example.
Wall texture without ambient occlusion
Wall texture with ambient occlusion
Pictured here is a recent experiment at generating local ambient occlusion based on the height. For each direction, march a given distance and keep the biggest tangent (height difference divided by distance). Finally, compute occlusion from the average tangent.
Limitations and future work
As you can see, the current design is a strong improvement over the previous one, and it provides creative expressivity. However, it still has limitations that we would like to address in the future.
For example, although it wasn’t a problem for this intro, we noticed that memory allocation could be an obstacle. The generation of a texture uses a single array of floats. For large textures with many layers, this can quickly hit the point where allocation fails. There are various ways to address this, but they all come with drawbacks. For example we could generate the textures tile by tile, which would scale better, but some operations like convolution would become less straightforward to implement.
Finally in this article despite using the word “material”, we have only talked about textures and never about shaders. Yet a material should arguably encompass the shading part as well. This contradiction reflects the limitation of our current design: texture generation and shading are two distinct parts, separated by a bridge. We have tried to make that bridge as simple to cross as possible, but what we really want is to treat the two as a whole. For example, if a material has static features as well as dynamic ones, we want to describe them in a same place. This is a difficult topic and we don’t know yet what could be a good solution but, let’s go one step at a time.
An experiment in trying to create a fabric texture similar to the earlier texture by Imadol Delgado.
Next up: meshes
Now that we’ve talked about textures, we invite you to keep reading to learn about mesh generation.
When making a demo in 64kB (or less!), many unexpected issues arise. One issue is that sitting floating point numbers can take quite a lot of space in the binary file. Floats are found everywhere: position of objects in the world, position of the camera, constants for the effects, colors in the texture generator, etc. In practice, we often don’t need as much precision as offered by floats. Can we take advantage of that to pack more data in a smaller space?
In many cases, it’s not important if an object is 2.2 or 2.21 meters high. Our goal is to reduce the amount of space used by those numbers. A float takes 4 bytes (8 bytes for a double). The actual size on disk can be reduced a bit with compression, but when there are thousands of floats, it’s still quite big (compression doesn’t work well as the binary data looks quite random). We can do better.
A naïve solution
Suppose we have some numbers between 0 and 1000, and we need a precision of 0.1. We could store those numbers as integers between 0 and 10000 and then divide by 10. Whether we use 32 bit or 16 bit integers in the code doesn’t make a difference: since we don’t use their full range of values, all these integers start with leading 0s. The compression code will detect such repetitive 0s and use around 13 bits per number in both cases.
The problem with this solution is that we need to do some processing at runtime. Each time we use a number, we have to convert it to a float and divide it by 10. If all our data is in a same place, we can loop over it. But if we have numbers all over our code base, we’ll also need to call a processor in all those places. This simple operation can be cumbersome and expensive in terms of space.
It turns out we can get rid of the processing, and directly use floating point numbers.
A note on IEEE floats
Floats are stored using the IEEE 754 standard. Some of them have a binary representation that contains lots of 0 and compress better than others.
Let’s look at two examples using a binary representation. The IEEE representation is not exactly the same as in the example below (it has to store the exponent), but almost.
6.25 -> 110.01
6.3 -> 110.010011…
In fact, 6.3 has no exact representation in base 2: the number stored is an approximation, and it would require an infinite number of digits to represent 6.3. On the other hand, the binary representation for 6.25 is compact and exact.
If we’re optimizing for size, we should prefer numbers like 6.25, that have a compact binary representation. For example, 0.125, 0.5, 0.75, 0.875 have at most 3 digits in binary after the decimal mark. The binary representation will have a lot of 0s at the end of the number, which will compress really well. The great thing is that we don’t need processing code anymore because we’re still using standard floats. We just store normal floats, but we try to use floats that include lots of 0 bits and will compress well.
To better understand IEEE representation, try some tools to visualize the floats. You’ll see how removing the last 1s will reduce the precision.
How much precision do we need?
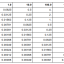
Floats are much more precise for values around 0. As our numbers get bigger, we’ll have less and less precision (or we’ll need more bits).
The table below is useful to check how much precision is needed. It tells you the worst error to expect based on the number of bits, and the scale of the input numbers. For example, if the input numbers are around 100 and we use 16 bits per float, the error will be at most 0.25. If we want the error to be less than 0.01, we need 21 bits per float.
Of course, each time you add a bit, you divide by two the expected error.
How to automate it?
An ad hoc solution is to remember this list of numbers and use them in the code when possible: 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875. An alternative is to use a list of macros from Iñigo Quilez. As Iñigo points out, this is not very elegant. Fortunately, this is hardly a problem because chances are this is not where most of your data lies.
64kB can actually contain a lot of data. Developers often rely on tools and custom editors to quickly modify and iterate on the data. In that case, we can easily use code to truncate the floating point numbers as part of the process. If you use a tool to set the camera (instead of manually entering the position numbers), that tool could round the floats for you.
Here is the function we use to round the binary representation of the floats:
// roundb(f, 15) => keep 15 bits in the float, set the other bits to zero
float roundb(float f, int bits) {
union { int i; float f; } num;
bits = 32 - bits; // assuming sizeof(int) == sizeof(float) == 4
num.f = f;
num.i = num.i + (1 << (bits - 1)); // round instead of truncate
num.i = num.i & (-1 << bits);
return num.f;
}
Just pass the float, choose how many bits you want to keep, and you’ll get a new float that will compress much better. If you generate C++ code with that number, be careful when printing it (make sure you print it with enough decimals):
printf("%.10ff\n", roundb(myinput, 12));
The great thing about this function is that we decide exactly how much precision we want to keep. If we desperately need space at some point, we can try to reduce that number and see what happens.
By applying this technique, we’ve managed to save several kilobytes on our 64kB executable.
Hopefully you will, too.
People not familiar with the demoscene often ask us how it works. How is it possible that a 64kB file contain so much? It can seem magical, since a typical music compressed as mp3 can be 100 times as big as our animations – not to mention the graphics. People also ask why other programs or games are getting so big. In 1990, when games had to fit on one or two floppy disks, they used only 1 or 2MB (which is still 20 times as much as our 64kB intros). Modern games now use 10-100 GB.
The reason for that is simple: Software engineering is all about making trade-offs. The typical trade-off is to use more memory to improve performance. But when you write a program, there are many more dimensions to consider. If you optimize on one dimension, you might lose on the other fronts. We make optimizations and trade-offs that wouldn’t make any sense outside the demoscene.
First, we optimize all the data we store in the binary. We use JSON files during the development for convenience, but then we generate compact C++ files to embed in the binary. This saves us a few kilobytes. Is it worth doing it? If you had to make a demo without the 64kB limit, you wouldn’t waste time on this. You’d prefer the 70kB executable instead. It’s almost the same.
Then, we compress our file (kkrunchy for 64kB intros, crinkler for 4kB intros). Compression slows down the startup time and antivirus software may complain about the file. It’s generally not a good deal. I bet you’ll choose the 300kB file instead. It’s still small, right?
We use compiler optimizations that will slightly slow down the execution to save bytes. That’s not what most users want. We disable language features like C++ exceptions, we give up object oriented programming (no inheritance) and we avoid external libraries – including the STL. This is a bad trade-off for most developers, because this slows down the development. Instead of rewriting existing functions, you’ll prefer the 600kB file.
Our music is computed in real-time (more precisely, we start a separate thread that fills the audio buffer). This means that our musician has to use a special synth and cannot use his favorite instruments. That’s a huge constraint that very few musicians would accept outside the demoscene. They will send you a mp3 file instead. You also need a mp3 player, and your demo is now 10MB.
Similarly, we generate all textures procedurally. And all the 3D models. For that, we write code and this is a lot of work. This adds a huge constraint on what we do (but constraints are fun and make us more creative). While procedural texture have lots of benefits, your graphists will prefer using their normal tools. You get JPEG images and – even if you’re careful – your demo size increases to 20MB.
At this point, you may wonder if it makes sense to write your own engine. It’s hard, error-prone and other people probably made one better than you would. You could use an existing engine and it would add at least 50MB. Of course, it’s still a simple application made by a small team, you can imagine what happens when you scale this up to a full game studio.
So demosceners achieve very small executable sizes because we care deeply about it. In many regards, demoscene works are an art form. We make decisions meant to support the artistic traits we’re pursuing. In this case, we’re willing to give up development velocity, flexibility, loading time, and a lot of potential content to fit everything in 64kB. Is it worth it? No idea, but it’s a lot of fun. You should try it.